Checking Cockroach : Distributed, Replicated, Sharded.

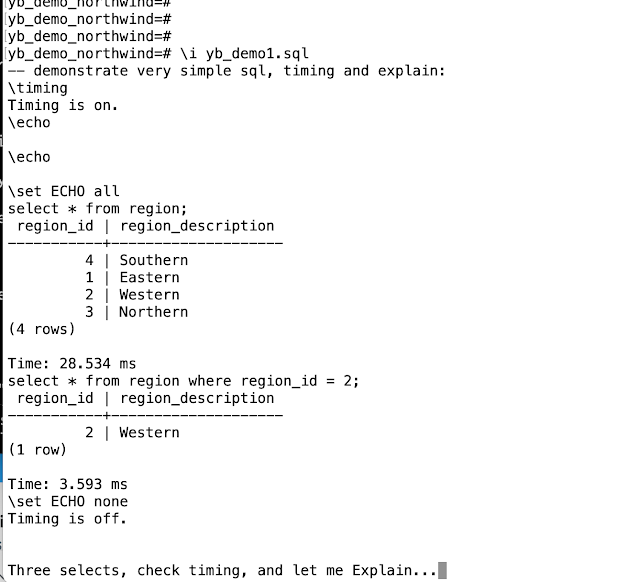
TL;DR: Some simple testing of data in a table to see how it is "replicated" and "sharded". Spoiler: cockroachDB replicates from the start, but it only shards (splits) when necessary. Hence on default settings you need to add about 512M to a table before any sharding (splitting) occurs. It seems to work Fine! Background: Distributed Databases, Replication and Sharding. The two different aspects covered by a Distributed Database are 1) Replication and 2) Distribution/Sharding. Replication: Offering resilience against outage (storage-, server- or network-faillure), and Sharding. Replication means there are multiple copies of the data in different storage-areas, or even in different physical locations. Sharding: Offering scalability to more-users and/or parallel processing of large sets. By having data in more manageable chunks (shards, partitions), it can be handled by multiple processes in parallel. Distribution or Sharding (can) offer both higher multi-user capacity...